온라인 팀 게임 매치메이킹 시스템 구현기
리그 오브 레전드의 매치메이킹 시스템을 직접 설계하고 구현해보았다
2026-07-01
1. 개요
최근에 친구의 추천으로 브롤스타즈 게임을 시작하게 되면서 주변 사람들과 함께 온라인 대전 게임을 즐기게 되었다. 그러다가 문득 매치메이킹 시스템에 대한 궁금증이 생겼다. 온라인 게임은 어떤 방식으로 유저들을 묶어 매치를 만드는걸까?
사실 매치메이킹 시스템은 브롤스타즈 뿐만 아니라 리그 오브 레전드, 도타 2, Call of Duty 등 다양한 온라인 게임들에서 사용된다. 만약 온라인 게임에서 자동으로 상대나 팀원을 찾아주는 기능이 있다면, 그 내부에는 어떤 형태로든 매치메이킹 시스템이 필요하기 때문이다.
그래서 이번 프로젝트에서는 매치메이킹 시스템을 직접 구현해보고자 한다. 프로젝트의 아이디어는 브롤스타즈에서 얻었지만, 실제 구현에서는 비교적 대중적인 게임인 리그 오브 레전드의 구조를 바탕으로 제작할 것이다. 또한 구현 과정에서 발생하는 여러 최적화 문제들에 대해 분석하고 해결 방법을 제시하고자 한다.
진행 기간: 5/22~5/29, 6/7~6/28 (4주)
전체 코드 보기: ⚠️
1.1 매치메이킹 시스템의 목표
Call of Duty 팀은 매치메이킹을 여러 요소를 고려해 로비(팀)을 구성하는 과정이라고 말한다. 주요 요소들로는 connection(인터넷 연결 속도), time to match(매칭 대기시간), skill(플레이어의 실력) 등을 제시했다. 특히 플레이어 실력 값의 영향을 낮춰 한 게임에서 유저간 실력 차이가 더 커졌을 때 경기 중 이탈률과 복귀율에 부정적인 영향이 증가했다고 말했다. 이처럼 경기의 공정성(각 팀의 승률이 50%에 가까운 정도, 즉 결과가 어떻게 될지 예측이 힘든 정도)는 플레이어의 만족도에 있어 중요한 요소이다. 한편, 플레이어는 게임을 하러 온 것이기 때문에 매칭 시간을 줄이는 것 또한 고려해야 할 부분이다. [1]
이번 프로젝트에서 구현하고자 하는 리그 오브 레전드에서는 각 플레이어가 선호하는 역할군(포지션)을 선택하는 시스템을 채택하고 있다. 따라서 플레이어가 최대한 자신이 원하는 역할군으로 선정되도록 하여 포지션 만족도(내가 선택한 포지션으로 플레이할 확률)를 올려야 할 것이다.
Riot Games는 리그 오브 레전드의 매치메이킹이 공정한 경기, 포지션 만족도, 적은 대기 시간 사이의 균형을 맞추는 것을 목표로 한다고 설명한다. [2] 이들 셋은 각각이 유저의 즐거움과 연결되는 중요한 요소이면서도 trade-off 관계를 이루는 요소들이다. 따라서 적절한 알고리즘과 평가 지표 설계를 통해 플레이어게 최적화된 매칭을 제공해주어야 한다.
1.2 프로젝트 목표
본 프로젝트의 목표는 리그 오브 레전드와 유사한 매치메이킹 시스템을 직접 구현하고, 구현 과정에서 발생하는 여러 현상 및 문제들을 분석하고 해결하는 것이다.
- 매치메이킹 시스템을 구현한다.
다음과 같은 기능들을 제공해야 한다.- 5 vs 5
- 파티/듀오 기능
- 각 팀마다 정확히 하나씩의 역할 분배 (top, jgl, mid, bot, sup)
- 매치메이킹 알고리즘의 품질을 평가하기 위한 지표를 설계한다. 또한 각 요소들 사이의 trade-off를 확인한다.
- 대기 시간
- 공정성 점수
- 역할 만족도
- 실제 구현 과정에서 발생하는 문제들을 확인하고 해결 방안을 제시한다.
- 특정 포지션 부족으로 인한 매칭 지연 문제
- secondary role 과배정 문제
- Autofill system
- 예상 매칭 시간 계산
기술 스택은 Python + FastAPI 이다.
2. 매치메이킹 시스템 기본 구현
첫 번째 단계에서는 파티/듀오 기능 · 역할군 기능과 같은 심화된 기능은 고려하지 않고, 오직 5 vs 5 팀 게임만을 위한 간단한 버전부터 구현을 할 것이다. 설계한 아키텍처는 다음과 같으며, 자세한 설명은 아래에서 이어서 한다.
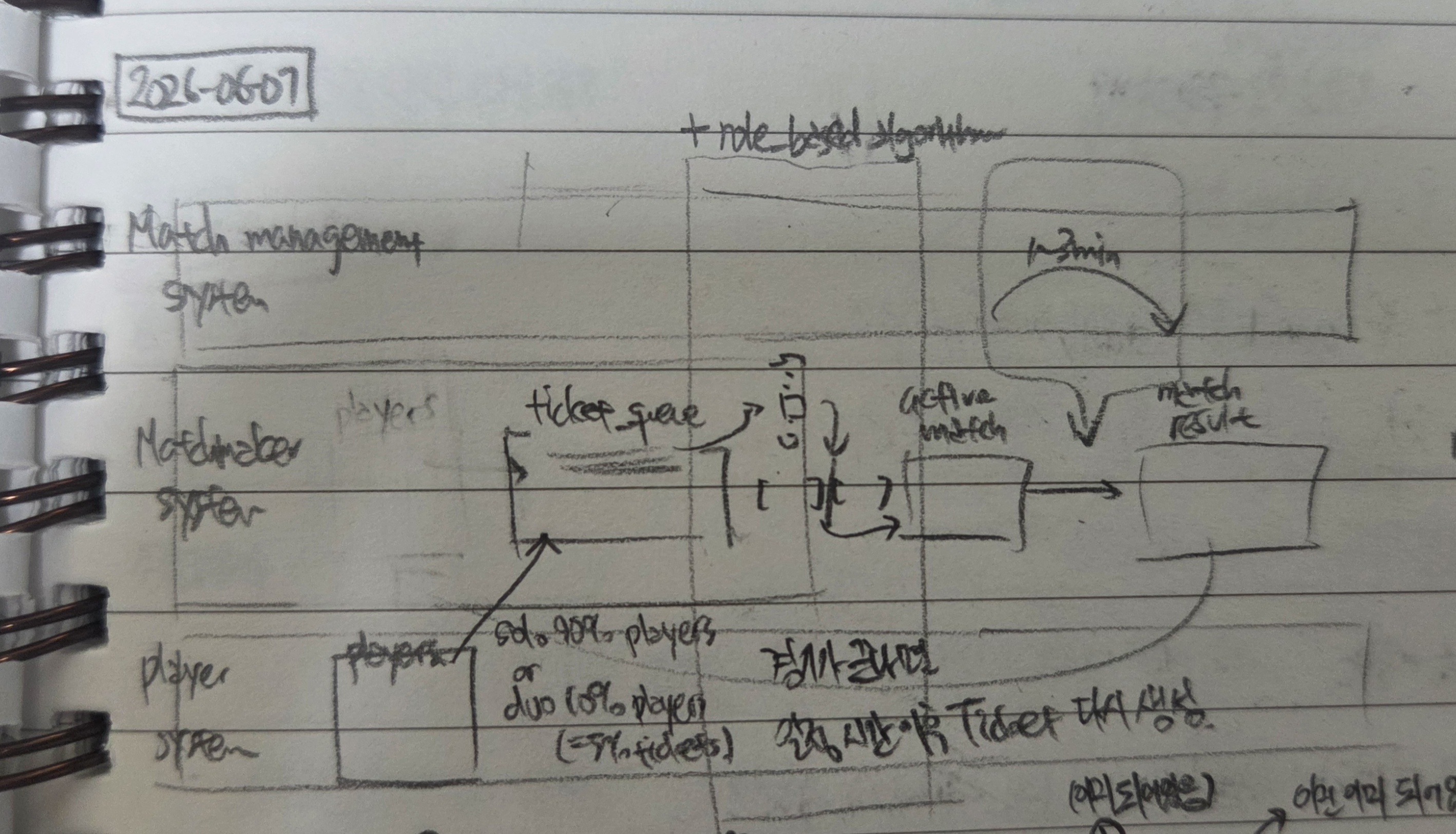 전체적인 설계
전체적인 설계
2.1 Player, Ticket, Matchmaker 구조
우선 게임을 설치한 플레이어들의 정보를 기록하기 위하여 Player 클래스를 만들어 주었다. 해당 클래스의 구성 요소는 다음과 같다.
class Region(str, Enum):
KR = "KR"
JP = "JP"
NA = "NA"
class Player(BaseModel):
id: str
name: str
region: Region
mmr: int = Field(ge=0, le=5000)
skill: int = Field(ge=0, le=5000)
# primary_role: Role
# secondary_role: Role
latency_ms: int = Field(ge=0, le=1000)id(Primary Key)와name은 각각 플레이어의 아이디와 이름을 저장한다.region은 플레이어의 지역(KO,JP,NA)으로, 서로 다른 지역에 있는 유저는 매칭될 수 없다는 제약 조건이 있다.- 또한 공정한 매칭을 위해 플레이어의 실력 값을 나타내는 지표인
mmr과skill필드를 만들었다.mmr은 매치메이킹 시스템에서 각 플레이어의 수준을 기록하기 위한 값으로서, 이 값을 통해 공정한 경기를 구성하는 등 적극적으로 읽고 수정할 수 있다. 반면skill은 플레이어의 내재된 실력을 표현하기 위한 값이어서 매치메이킹에서는 사용되지 않으며, 각 경기의 결과를 결정하기 위해 제한적으로 사용된다. - 마지막으로
latency_ms는 서버와 유저 사이 통신에서의 지연 값을 뜻한다. 공정한 경기를 위해서는mmr과latency_ms값이 비슷한 사람들끼리 매칭되어야 할 것이다. primary_role과secondary_role필드는 추후에 관련 기능을 구현할 때 다시 설명하겠다.
class Ticket(BaseModel):
id: str
players: Player
# players: list[Player] = Field(min_length=1, max_length=2) # 이렇게 확장 가능
queued_at: datetime이후에 해당 플레이어가 큐를 돌리게 되면, 해당 플레이어의 정보는 ticket에 담겨 ticket_queue 리스트에 담기게 된다. 이 때 Player와 ticket을 구분한 이유는 다음과 같다.
- 첫 째, 한 플레이어가 여러번의 게임 참가 요청을 보낼 수 있다.
- 둘 째, Player의 정보는 계속해서 바뀌며 재사용되는 값이지만 ticket은 한번 사용되면 버려지는 값이다.
- 셋 째, Duo 등 여러 명이 동시에 큐를 돌릴 경우 한 개의 요청에 여러 명의 player가 포함될 수 있는 구조가 필요하다.
이러한 측면들에서 바라봤을 때 Player와 Ticket을 구분하는 구조가 타당하다.
이렇게 ticket_queue 리스트에 ticket들이 쌓이게 되면, Matchmaker는 해당 리스트를 계속해서 조회하면서 적절한 티켓들을 뽑아 매치를 구성한다. 해당 알고리즘이 바로 매치메이킹 시스템의 핵심이라고 할 수 있다. 위에서 말했듯이 플레이어가 흥미를 느낄 수 있도록 공정한 경기를 구성하면서도, 매치메이킹에만 너무 오래 기다리지 않도록 충분히 빠른 시간 내에 경기를 만들어야 한다. 둘 사이의 균형을 잘 맞추어야 하는 것이다.
매치메이킹이 만족해야하는 최소 조건들을 바탕으로 간단한 형태의 구현을 해보았다. Matchmaker는 아래의 알고리즘을 무한히 반복한다.
[알고리즘 요약 사진]
-
티켓을 가장 오래된 순으로 정렬했을 때 앞에서 N(=30)개를 선택해 anchor로 선정하고, 각 anchor에 대해 다음 과정을 반복한다:
1-1. 제약 조건을 만족하는 티켓들을 선정한다.
경기의 제약 조건은 크게 hard constraints와 soft constraints로 구분할 수 있다. Hard constrains는 무조건 지켜야만 하는 조건이며, soft constraints는 지키면 좋지만 다른 요소가 더 중요한 경우 생략할 수 있는 조건을 말한다. 1-1단계에서는 hard constaints에 해당하는, 무조건 지켜야 하는 조건들을 검수한다. 이에는 anchor 티켓과 지역이 동일해야 하고, mmr 및 latency가 특정 범위 내에 있어야 한다는 조건을 선정했다.backend/app/core/matchmaker.py nearby_tickets = [ ticket for ticket in queue if ticket.id not in used_ticket_ids # 아직 매칭되지 않았으며 and self._ticket_region(ticket) == anchor_region # anchor와 지역이 같고 and low_mmr <= ticket.average_mmr <= high_mmr # mmr과 and self._compatible_latency(anchor, ticket, config) # latency가 비슷한 티켓을 모은다. and len(ticket.players) <= config.team_size ]1-2. 선정된 티켓들을 점수에 따라 정렬하고 점수가 높은 순으로 M(=14)개만 선택한다.
이렇게 anchor와 매치가 이루어지면 안되는 ticket들은 전부 탈락했다. 그러나 남은 ticket 중에서도 비교적 anchor와 매치가 되면 좋은 ticket들이 있을것이고, 별로 좋지 않은 ticket들이 있을 것이다. 이들은 내부적으로 정의된_candidate_ticket_score함수를 통해 anchor ticket과의 매칭 적합도가 결정된다. 이 점수는 mmr 차이, latency 차이, 대기 시간의 가중합으로 정의되며 구체적인 식은 다음과 같다.backend/app/core/matchmaker.py def _candidate_ticket_score(...) -> float: return self._weighted_candidate_ticket_score( mmr_value=abs(ticket.average_mmr - anchor.average_mmr), latency_value=abs(ticket.average_latency - anchor.average_latency), wait_seconds=ticket.wait_seconds, config=config, ) def _weighted_candidate_ticket_score(...) -> float: mmr_score = self._ratio(mmr_value, config.match_score_mmr_normalizer) # 280 latency_score = self._ratio(latency_value, config.match_max_latency_gap) # 12 wait_bonus = min(wait_seconds / config.candidate_wait_score_cap_seconds, 1.0) # 300 return ( mmr_score * config.candidate_mmr_score_weight # 0.7 + latency_score * config.candidate_latency_score_weight # 0.1 - wait_bonus * config.candidate_wait_score_weight # 0.2 )그리고 정렬된 ticket들 중
MAX_CANDIDATE_POOL(=14)개만 남겨놓는다.1-3. 이들 중 가장 좋은 경기가 나올 것 같은 조합 10명을 뽑는다.
이제 14개의 ticket들 중에서, 각 10개씩의 ticket을 뽑아 5v5 경기를 구성할 수 있는 경우의 수를 모두 살펴본다. 그리고 플레이어들 사이의
mmr과latency_ms값의 표준편차가 가장 작은 조합을 선택한다. 이를 통해 각 팀의 평균 mmr과 latency가 비슷한, 즉 공정한 경기가 될 가능성이 높은 조합을 선정할 수 있다.backend/app/core/matchmaker.py def _candidate_group_score(...) -> tuple[float, datetime]: players = self._players_from_tickets(tickets) mmr_stddev = self._population_stddev(player.mmr for player in players) latency_stddev = self._population_stddev( player.latency_ms for player in players ) oldest_wait = max(ticket.wait_seconds for ticket in tickets) oldest_queued_at = min(ticket.queued_at for ticket in tickets) return ( self._weighted_candidate_group_score( mmr_value=mmr_stddev, latency_value=latency_stddev, wait_seconds=oldest_wait, config=config, ), oldest_queued_at, ) def _weighted_candidate_group_score(...) -> float: mmr_score = self._ratio(mmr_value, config.match_score_mmr_normalizer) latency_score = self._ratio(latency_value, config.match_score_latency_normalizer) wait_bonus = min(wait_seconds / config.candidate_wait_score_cap_seconds, 1.0) return ( mmr_score * config.candidate_group_mmr_score_weight + latency_score * config.candidate_group_latency_score_weight - wait_bonus * config.candidate_group_wait_score_weight )1-4. 10명을 5v5로 나누는 방법 중 가장 점수가 높은 조합을 선택한다.
마지막으로 10명의 사람들을 가장 공정한 조합이 되도록 5v5로 분배한다. 여기서는 각 팀의 평균
mmr과latency_ms값의 차이를 공정성의 척도로 계산하였다. (해당 평가 점수에 대한 자세한 설명은 아래에서 다시 나온다.)backend/app/core/matchmaker.py def split_teams(...) -> tuple[list[Ticket], list[Ticket]]: if self._ticket_player_count(tickets) != config.match_size: return [], [] best_blue: list[Ticket] = [] best_red: list[Ticket] = [] best_quality: MatchQuality | None = None ticket_ids = {ticket.id for ticket in tickets} for group_size in range(1, len(tickets)): for blue_combo in combinations(tickets, group_size): blue_tickets = list(blue_combo) if self._ticket_player_count(blue_tickets) != config.team_size: continue blue_ids = {ticket.id for ticket in blue_tickets} red_tickets = [ticket for ticket in tickets if ticket.id not in blue_ids] if blue_ids == ticket_ids: continue if self._ticket_player_count(red_tickets) != config.team_size: continue quality = self.score_match(blue_tickets, red_tickets, config) if best_quality is None or quality.overall < best_quality.overall: best_blue = blue_tickets best_red = red_tickets best_quality = quality return best_blue, best_red -
이렇게 선정된 L개의 경기가 시작된다.
2.2 매치 관리 시스템
각 경기가 시작된 후에는 실제 플레이어들의 플레이에 따라 승패가 갈린다. 그러나 내 프로젝트의 경우에는 실제 플레이어가 없기 때문에 임의로 경기의 결과를 결정해주어야 한다. 이를 위해서 플레이어의 가상의 실력 값인 skill 필드를 설정하였었다.
해당 프로젝트에서는 확률 계산을 위해 ELO 레이팅 시스템을 채택했다. 우선 다음과 같은 식을 통해 블루 팀의 승률을 계산한다.
그 다음에는 random.random()을 통해 0과 1 사이의 난수를 생성하고, 위에서 계산한 확률과 비교하여 승패를 결정한다. 만약 난수가 계산된 확률보다 작다면 blue 팀이 승리하고, 그렇지 않다면 red 팀이 승리하게 된다.
마지막으로 결정된 승패에 따라 각 플레이어의 mmr 값을 업데이트한다. 승리한 팀의 플레이어들은 mmr 값이 증가하고, 패배한 팀의 플레이어들은 mmr 값이 감소한다. 이 때 mmr 값의 변화량은 다음과 같이 계산된다.
(승리한 팀)
(패배한 팀)
여기서 는 가중치 값이며 은 이전에 예측된 승률이다. 여기서 주의할 점은, 아래 식에서의 승률은 skill 값이 아닌 mmr 값을 기반으로 계산된 승률이라는 것이다. 매치메이킹 시스템은 서버 상에 있는 플레이어의 실력 지표 mmr만을 알고 있기 때문이다.
참고로 경기 시간은 20~40초 중에서 무작위로 결정된다.
2.3 플레이어 생애주기 관리 시스템 (플레이어 시스템)
시뮬레이션을 위해서는 각 플레이어가 큐를 돌리고, 경기가 끝나면 mmr이 업데이트되고, 다시 큐를 돌리는 등의 플레이어 lifecycle을 관리하는 시스템이 필요하다. 이는 매치메이킹 시스템 자체와는 아무 관련이 없는, 오직 시뮬레이션을 위한 시스템이기 때문에 따로 분리하였다.
일단 시뮬레이션이 시작되면 1000명의 플레이어를 생성한다. mmr과 skill 값은 정규분포 을 따르고, latency_ms 값은 정규분포 을 따르도록 설정했다. 또한 region은 KO, JP, NA 중에서 랜덤으로 선택되도록 했으며, 이 때 비율은 이다.
FIRST_NAMES = ["Ari", ..., "Tae"]
REGION_VALUES = list(Region)
REGION_LATENCY_BASE = {
Region.KR: 28,
Region.JP: 48,
Region.NA: 95,
}
def generate_player(index: int | None = None) -> Player:
id = new_id("p")
suffix = index if index is not None else random.randint(1000, 9999)
name = f"{random.choice(FIRST_NAMES)}{suffix}"
region = random.choices(REGION_VALUES, weights=[0.72, 0.18, 0.10], k=1)[0]
mmr = int(random.gauss(1500, 280))
mmr = max(700, min(2600, mmr))
skill = int(random.gauss(1500, 280))
skill = max(700, min(2600, skill))
base_latency = REGION_LATENCY_BASE[region]
latency_ms = max(10, int(random.gauss(base_latency, 12)))
return Player(
id=id,
name=name,
mmr=mmr,
skill=skill,
region=region,
latency_ms=latency_ms,
)플레이어는 경기가 끝나면 랜덤으로 1~3초를 쉬고 다시 큐를 돌린다.
2.4. 점수 설계 및 trade-off 관찰
이제 매칭이 완료된 경기들이 얼마나 좋은 매칭이었는지 평가하기 위해 지표를 설계해야 한다. 총 2개의 지표를 정의하였다.
- 대기 시간은 각 플레이어가 큐를 돌린 시점부터 매칭이 완료될 때까지 걸린 시간의 평균으로 정의하였다. 대기 시간이 낮을수록 플레이어가 매칭을 기다리는 시간이 짧다는 뜻이며, 이는 플레이어의 만족도를 높이는 요소이다.
- 공정성 점수는 [각 팀의 평균 mmr 차이의 절댓값]과 [평균 latency 차이의 절댓값]의 가중합으로 정의하였다. 공정성 점수가 낮을수록 양 팀의 평균 mmr과 latency가 비슷하다는 뜻이며, 이는 경기가 공정하게 진행될 가능성이 높다는 것을 의미한다. (참고로 공정성 점수는 낮을수록 좋다.)
그리고 두 지표 사이의 관계를 확인하기 위해 설정 값을 바꿔가며 시뮬레이션을 돌려보았다. 총 9가지의 설정 값마다 각각 10번씩 실험하였으며, 플레이어의 수는 1000명으로 설정하였다.
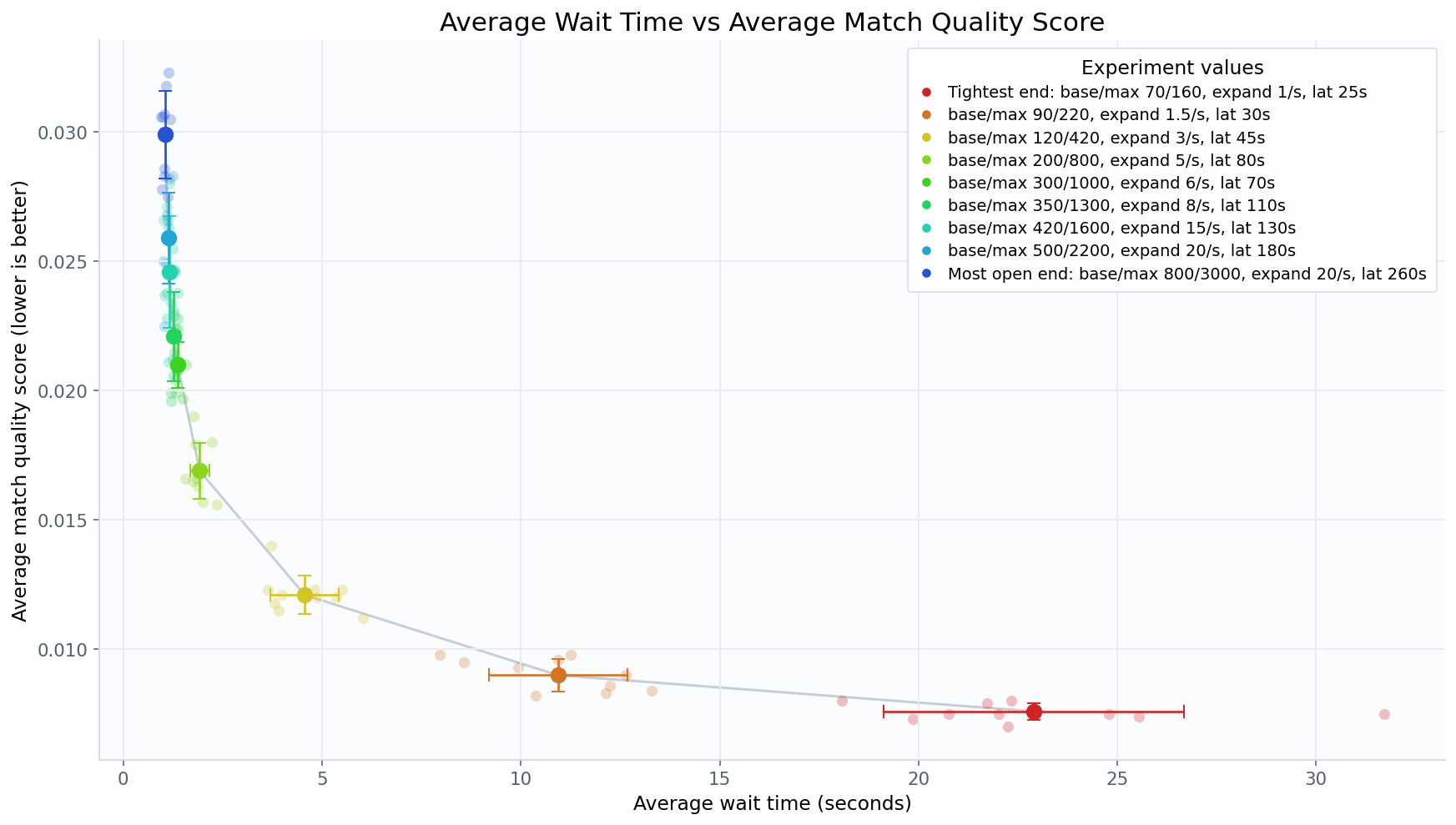 평균 대기 시간과 평균 공정성 점수 사이의 그래프
평균 대기 시간과 평균 공정성 점수 사이의 그래프
위와 같이 대기 시간과 공정성 점수 사이에 반비례 관계가 있었다. 이렇게 두 요소 사이에는 trade-off 관계가 존재함을 확인할 수 있다.
3. 듀오 기능 구현
3.1. 기본 구현
듀오 기능을 구현하기 위해서는 크게 두 가지를 고려해야 한다. 첫 번째는, 각 티켓이 최대 2명의 플레이어를 포함할 수 있도록 확장하는 것이다. 이는 다음과 같이 Ticket 모델의 필드를 수정함으로써 구현할 수 있다.
class Ticket(BaseModel):
id: str
players: Player
players: list[Player] = Field(min_length=1, max_length=2)
queued_at: datetime두 번째로는, 플레이어 일부가 짝을 이루어 큐를 돌릴 수 있도록 구현해야 한다. 이를 위해 Player system에서 10% 확률로 두 명씩 묶어서 ticket을 만드는 로직을 구현했다. 만약 특정 플레이어가 10% 확률에 걸려 듀오 큐를 돌리기로 결정되었을 때, 만약 대기하고 있는 사람이 있다면 그 사람이랑 묶어서 duo ticket을 만들고, 없다면 그 플레이어가 대기하는 식으로 구현하였다.
3.2. 평가 점수 변경 (Duo parity 도입)
5v5의 팀게임에서 듀오 큐가 가지는 이점은 명확하다. 서로의 단점을 보완해주는 플레이를 할 수 있으며, 의사소통 또한 더욱 원활해진다.만약 듀오 큐가 한쪽 팀에만 몰리게 된다면 형평성 문제가 생길 수 있다. 따라서 매치의 점수를 계산할 때 duo ticket이 치우치지 않은 정도를 반영하고자 한다. 이를 위해 duo parity라는 지표를 새로 추가하였으며, 이는 [양 팀의 duo ticket 개수의 차이]를 normalizer로 나눈 값으로 정의하였다.
def overall(self) -> float:
mmr_score = self._ratio(self.mmr_gap, self.mmr_score_normalizer)
latency_score = self._ratio(self.latency_gap, self.latency_score_normalizer)
duo_parity_score = self._ratio(
self.duo_parity_gap,
self.duo_parity_score_normalizer,
)
return (
mmr_score * MATCH_QUALITY_MMR_SCORE_WEIGHT
+ latency_score * MATCH_QUALITY_LATENCY_SCORE_WEIGHT
+ duo_parity_score * MATCH_QUALITY_DUO_PARITY_SCORE_WEIGHT
)여기서 normalizer 값을 고안한 이유 및 방식은 다음과 같다. 아까 mmr과 latency_ms에 대한 normalizer 값을 떠올려보면 모두 를 기준으로 두었었다. 왜냐하면, mmr 값이 280만큼 차이 나는 것과 latency_ms 값이 12만큼 차이나는 것이 확률적으로 동등한 사건이라고 볼 수 있기 때문이다.
이제 duo parity에 해당하는 normalizer 값을 정하기 위해서는, "5v5 경기에서 양 팀의 듀오 큐 개수 차이를 분포로 나타내었을 때, 에 해당하는 값은 얼마인가?" 라는 문제를 풀어야 한다. 실제로 계산해보면 해당 분포의 표준편차는 이 됨을 알 수 있으며, 따라서 해당 값을 normalizer로 설정하였다.
그런데 실제로 시뮬레이션을 돌려보면 여전히 한 팀에만 duo가 몰리는 현상을 볼 수 있었다. (양 팀의 duo 수가 정확히 같은 매치는 전체의 55% 였다. 임시방편으로 duo parity에 가중치를 많이 두면 이 현상이 줄어들긴 하지만, 계속해서 줄어들지는 않는다.)
이러한 이유는 근본적으로 알고리즘에 있다고 생각했다. 후보 ticket을 14개를 선정한 뒤 이것들만을 사용해서 가장 공정한 매칭을 고르는데, 만약 후보군에 duo ticket이 1개밖에 없다면 어떤 경우에서도 양 쪽의 듀오 ticket의 수를 맞출 수가 없다.
- 그럼 duo ticket이 양쪽 둘다 0개면 된다고 생각할 수 있지만, 그 한 개 남은 duo ticket이 anchor인 경우에는 무조건 매칭에 포함이 되어야 하므로, 결국 한 쪽 팀에만 duo ticket이 생기게 된다.
- 또한 후보 ticket을 더 많이 고르면 될 것 아니냐고 생각할 수 있다. 그러나 그렇게 되면 경우의 수가 급격하게 늘어나 한 tick당 소요 시간이 늘어나게 된다. 단순 계산으로 후보 ticket을 개를 고른다고 하면 계산해보아야 하는 팀의 개수는 이다. 이 값은 일 때 에서 시작해 일 때 , 일 때 , 일 때 등 매우 빠르게 증가한다. 이러한 방식은 duo parity를 줄일수는 있겠지만 매칭 시간이 늘어나게 되므로 근본적인 해결책은 될 수 없다.
그래서 duo ticket의 parity를 맞추기 위해서는 단순히 soft constraints의 점수에만 기댈 것이 아니라, 알고리즘 상에서 적극적으로 duo 개수를 맞추기 위한 노력을 해야 한다는 결론을 내었다. (특히, 내가 가중치를 조정함에 따라서 원하는 duo parity 점수대가 되도록 직접 조절할 수 있다면 실제 서비스 관리시 큰 도움이 될 것이다. 실제 사용자들의 데이터와 피드백을 토대로 조정할 수 있을 것이니 말이다.)
나는 다음과 같은 간단한 해결 방법을 생각해보았다.
- anchor가 duo ticket일 경우 강제적으로 duo ticket을 1개 더 넣어준다.(만약 존재한다면. ticket들 중 가장 성적이 높은 ticket을 넣어준다) 이를 통해 양쪽에 duo ticket이 하나씩 있는 매치가 고려 대상이 될 수 있도록 한다.
그러면 candidate_group_score 함수에서의 duo parity 가중치 값에 따라 다음과 같은 결과를 얻을 수 있다.
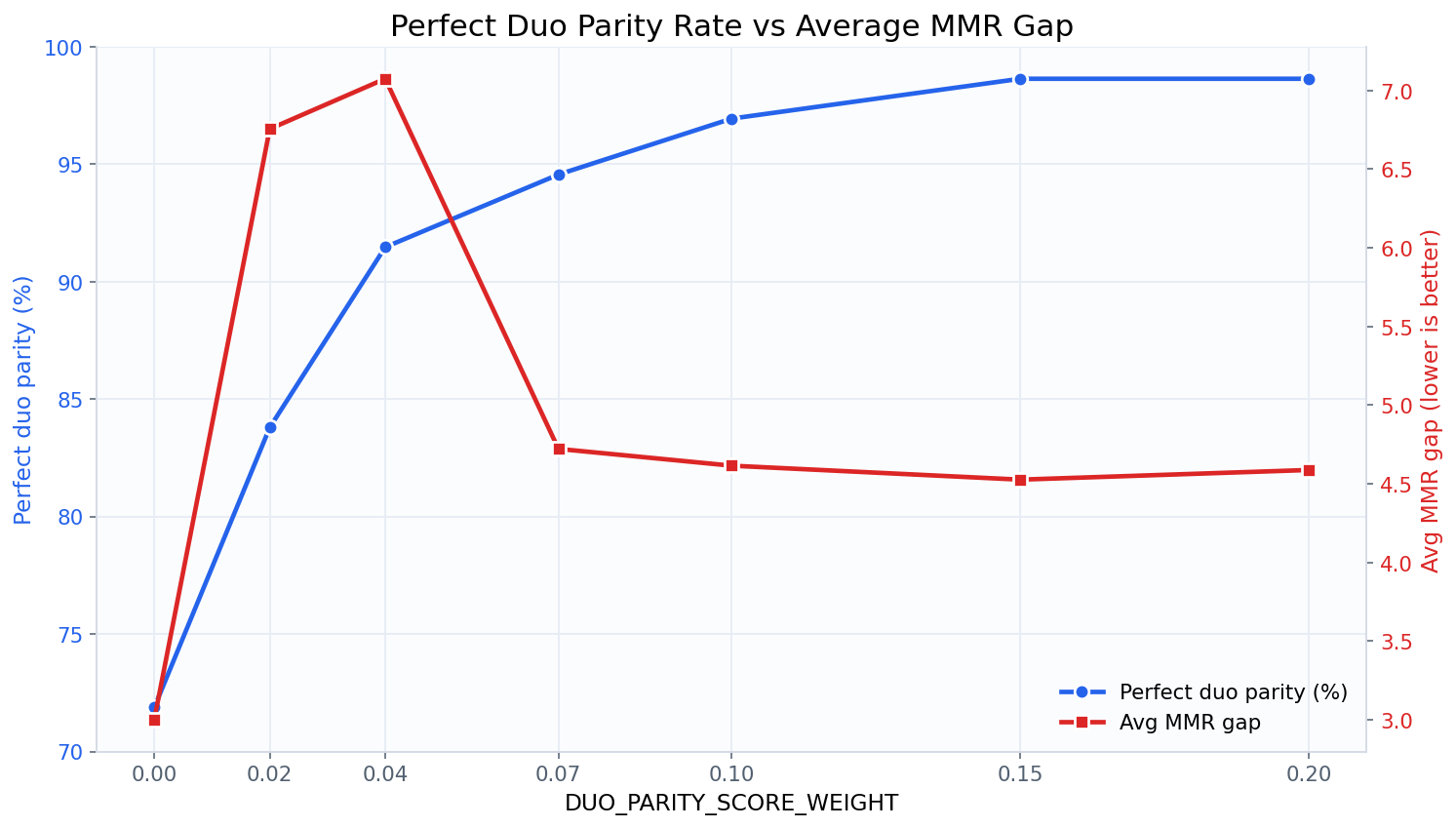 duo parity 가중치 값에 따른 duo parity와 평균 MMR 차이 그래프
duo parity 가중치 값에 따른 duo parity와 평균 MMR 차이 그래프
일단 강제적으로 duo ticket을 1개 더 넣어준 것 만으로도 perfect duo parity rate가 약 72로 높게 올라간 것을 확인할 수 있다 (DUO_PARITY_SCORE_WEIGHT=0).
또한 해당 가중치 값을 올려줌에 따라 perfect duo parity rate가 99%까지 증가함을 볼 수 있다. 물론 이전에 비해서 Avg MMR Gap과 같은 공정성 점수는 조금 안 좋아지긴 한다. 실제 게임 운영시에는 플레이어의 만족도 등의 데이터를 참고하여 최적의 가중치 값을 설정하면 될 것이다.
4. 역할군 기능 구현
이제 각 플레이어가 선호하는 역할군을 선택하여 큐를 돌렸을 때, 한 팀에 각 역할군들(top, jgl, mid, bot, sup)이 정확히 한 명씩 있도록 하는 시스템을 구현해보자.
4.1. 역할군 클래스 구현 및 지표 설계
역할군 구현을 위한 기본 가정은 다음과 같다.
- 역할군에는 top, jgl, mid, bot, sup의 총 5가지가 있다.
- 각 팀에서는 정확히 한 명씩의 역할군이 필요하다.
- 각 플레이어는 primary role과 secondary role을 선택한다.
(primary role은 플레이어가 가장 선호하는 역할군이며, secondary role은 primary role 다음으로 선호하는 역할군이다.) - 각 플레이어는 각 경기에서 무조건 둘 중 하나의 역할군으로 매칭이 되어야 한다.
- 해당 선호는 변하지 않는다고 가정한다.
이를 바탕으로 Player 클래스를 수정해보면 다음과 같다.
class Role(str, Enum):
TOP = "top"
JGL = "jgl"
MID = "mid"
BOT = "bot"
SUP = "sup"
class Region(str, Enum):
KR = "KR"
JP = "JP"
NA = "NA"
class Player(BaseModel):
id: str
name: str
region: Region
mmr: int = Field(ge=0, le=5000)
skill: int = Field(ge=0, le=5000)
primary_role: Role
secondary_role: Role
latency_ms: int = Field(ge=0, le=1000)그리고 시뮬레이션이 시작될 때 플레이어 시스템에서 각 플레이어의 primary role과 secondary role을 랜덤으로 선택하도록 구현하였다. 이 때 primary role은 5가지 역할군 중에서 균등하게 선택되도록 하였으며, secondary role은 primary role과 겹치지 않도록 나머지 4가지 역할군 중에서 균등하게 선택되도록 하였다.
FIRST_NAMES = ["Ari", ..., "Tae"]
ROLE_VALUES = list(Role)
REGION_VALUES = list(Region)
REGION_LATENCY_BASE = {
Region.KR: 28,
Region.JP: 48,
Region.NA: 95,
}
def generate_player(index: int | None = None) -> Player:
id = new_id("p")
suffix = index if index is not None else random.randint(1000, 9999)
name = f"{random.choice(FIRST_NAMES)}{suffix}"
primary = random.choice(ROLE_VALUES)
secondary_choices = [role for role in ROLE_VALUES if role != primary]
secondary = random.choice(secondary_choices)
region = random.choices(REGION_VALUES, weights=[0.72, 0.18, 0.10], k=1)[0]
mmr = int(random.gauss(1500, 280))
mmr = max(700, min(2600, mmr))
skill = int(random.gauss(1500, 280))
skill = max(700, min(2600, skill))
base_latency = REGION_LATENCY_BASE[region]
latency_ms = max(10, int(random.gauss(base_latency, 12)))
return Player(
id=id,
name=name,
mmr=mmr,
skill=skill,
primary_role=primary,
secondary_role=secondary,
region=region,
latency_ms=latency_ms,
)점수 지표 역시 위에서 duo parity 관련 지표를 정의할 떄와 유사하게 정의하였다. 역할군 만족도는 한 팀에서 [secondary role에 배정된 플레이어의 수]를 normalizer로 나눈 값으로 정의된다. (즉, 작을수록 좋다.) 그리고 normalizer 값은 secondary role에 배정된 플레이어 수의 분포에서 에 해당하는 값으로 설정하였으며, 이 값은 이다.
4.2. 기본 구현과 문제점들
이제 매칭시 각 팀에는 정확히 한 명씩의 역할군이 배정되도록 구현해보자. 우선 가장 간단하게 다음과 같은 방식을 구현하였다.
- 이전과 동일한 방식으로 5vs5 대전을 구성한다.
- 이제 각 팀에서 각 유저마다 primary role과 secondary role을 사용하는 모든 경우의 수(2^5=32가지)를 고려하여 가장 역할군 만족도가 높은 배정 방식을 선택한다.
- 만약 역할 배정이 불가능하다면 해당 매칭은 폐기된다.
그러나 이와 같은 방식으로 구현했을 때 몇 가지 문제점이 발생하였다.
4.2.1. 특정 역할군 부족으로 인한 매칭 지연 문제
게임을 운영하다 보면 특정 역할군을 선택하는 플레이어가 부족한 경우가 발생할 수 있다. 예를 들어, sup 역할군을 primary role과 secondary role중 하나로도 선택하지 않은 플레이어들이 많다면, 매칭을 구성할 때 sup 역할군이 부족하게 되어 자연스럽게 대기 시간과 Role 만족도가 내려가게 될 것이다.
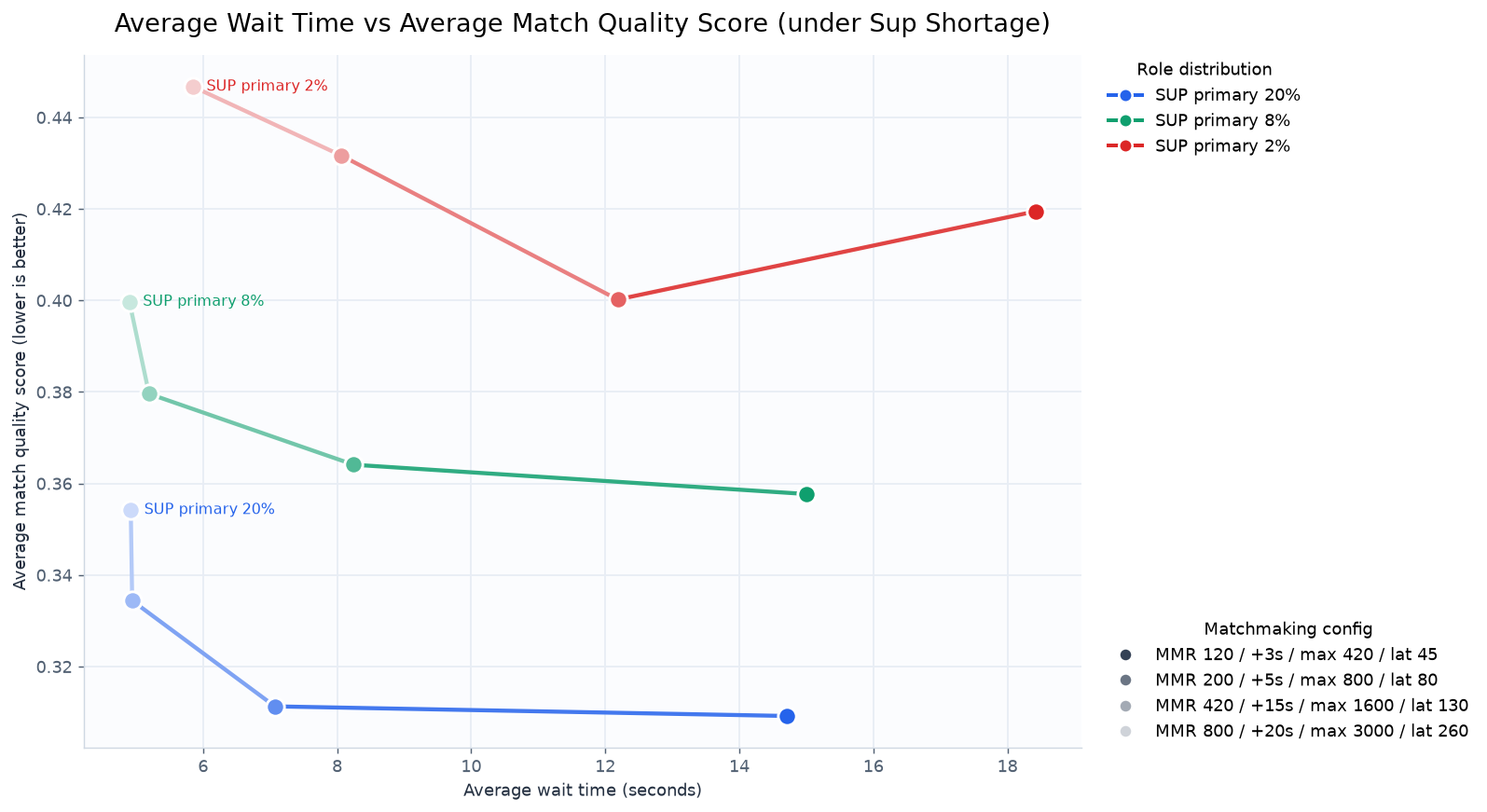 평균 대기 시간에 대한 공정성 점수의 그래프
평균 대기 시간에 대한 공정성 점수의 그래프
실제로도 sup 역할군을 primary role로 선택한 플레이어의 비율을 20%에서 8%, 2% 등으로 낮춰가며 평균 대기 시간과 공정성 점수를 측정하면, 대기 시간과 공정성 점수가 눈에 띄게 올라가는 것을 확인할 수 있다.
4.2.2. 인기 역할군 primary role, 비인기 역할군 secondary role 선택 시 secondary role 과배정 문제
또한 위의 알고리즘 때문에 다음과 같은 문제점도 발생하는 것을 관찰할 수 있다. 이를테면 어떤 플레이어가 priary role로 인기 역할군인 mid를 선택하고, secondary role로 비인기 역할군인 sup을 선택했다고 하자. 이제 역할군 배정이 이루어질 때 mid 역할군의 경우에는 인기 역할군이라서 다른 플레이어들이 배정받을 경우의 수가 많은 반면, sup 역할군은 해당 플레이어만 선택했기 때문에 반드시 배정받아야만하는 경우의 수가 많다. 각 팀에서 적어도 한 명은 sup 역할군을 배정받아야 하므로, 해당 플레이어는 primary role이 아닌 secondary role로 배정되는 것이다.
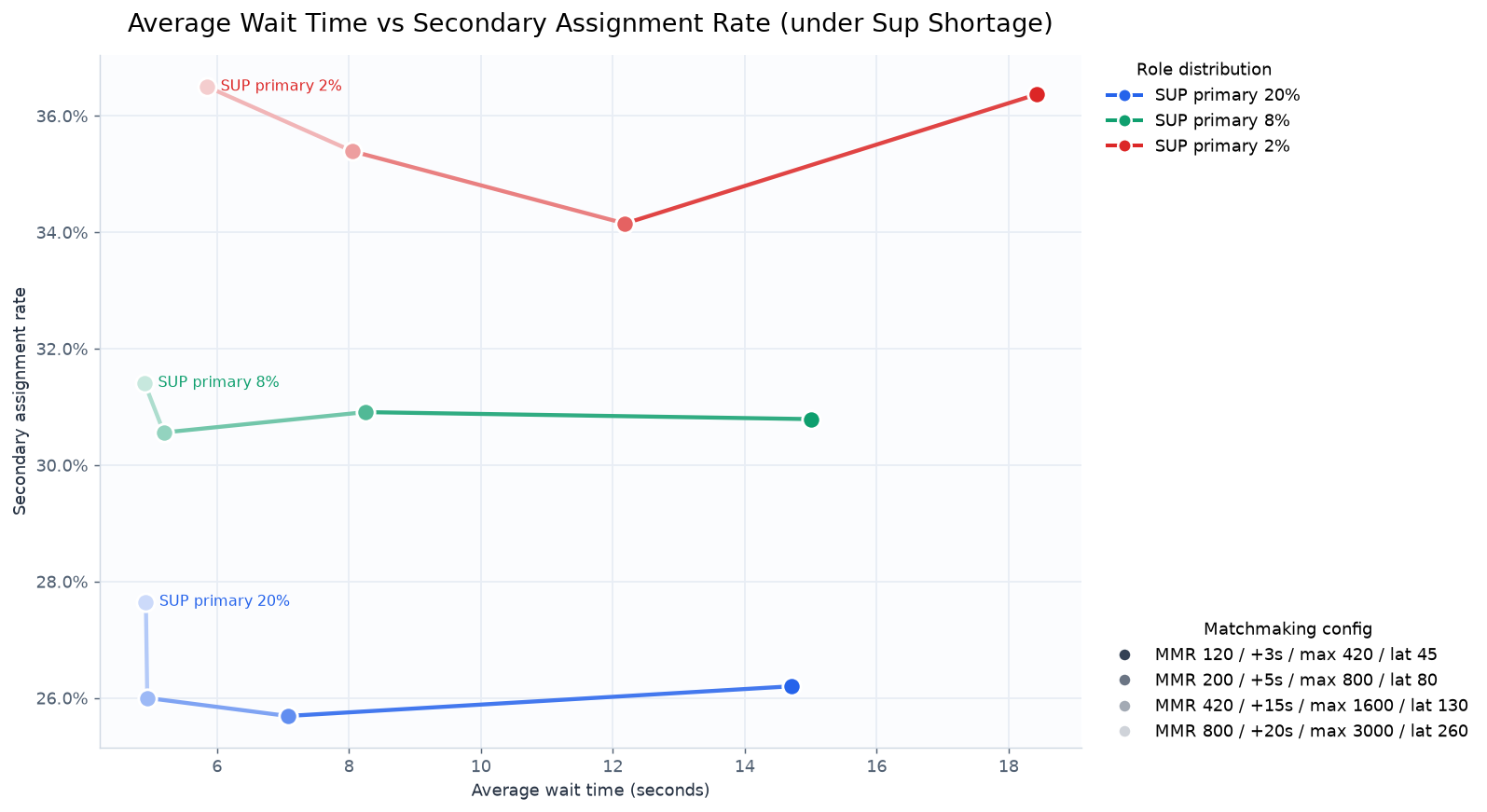 평균 대기 시간에 대한 secondary role 배정 비율의 그래프
평균 대기 시간에 대한 secondary role 배정 비율의 그래프
그래프에서 볼 수 있듯이 약 26% 대이던 secondary role 배정 비율은 sup 역할군의 선호 비율이 낮아짐에 따라 31%(초록), 35%(빨강) 등으로 지속적으로 증가한다.
4.3. 더욱 최적화된 구현 - Autofill 시스템
해당 문제점들을 해결하기 위해서 2가지의 해결 방안을 고안해보았다.
-
처음에 정렬시 role의 희귀도에 따라 bonus를 주는 방식 구현
맨 처음에 1차 정렬(
candidate_ticket_score)을 할 때, 각 플레이어가 선택한 primary role과 secondary role의 희귀도에 따라 bonus를 주는 방식으로 구현하였다. 예를 들어,sup역할군을 primary role로 선택한 플레이어가 10%밖에 없다면, 해당 플레이어에게 bonus를 주어 다른 플레이어들보다 우선적으로 매칭되도록 하는 것이다. 이렇게 하면 부족한 역할군의 플레이어들이 순위의 상위권에 더 많이 등장하므로, 이후 10명의 플레이어들을 골랐을 때 균등한 역할군 분포가 나올 확률이 높아진다.(코드)
참고로 해당 단계에서 최종적으로 정의된 가중치 값들은 다음과 같다.
score function mmr latency_ms duo_parity wait_seconds role_satisfaction role_bonus candidate_ticket_score 0.63 0.09 - 0.18 X 0.1 candidate_group_score 0.56 0.08 0.2 0.16 X - score_match 0.7 0.1 0.2 - O - -
Autofill 시스템 도입
해당 시스템은 기존 리그 오브 레전드에서 도입한 시스템이다. 롤을 즐겨 하는 사람이라면, 나는 분명 선호 역할군으로
top과mid를 선택했는데 갑자기sup에 배정되는 경험을 한 적이 있을것이다. 이는 리그 오브 레전드에서 도입한 Autofill 시스템 떄문이다. 만약 특정 역할군에 유저가 너무 적을 경우, 해당 역할군을 선택하지 않는 플레이어들 일부를 강제로 해당 역할군에 배정시켜버리는 방법을 통해 대기 시간을 줄이고 나머지 플레이어들의 역할 만족도를 올리는 방식이다. 실제로 Riot Games에서 제시한 자료를 보면, Autofill 시스템을 도입함으로써 대략 28%에 달하던 secondary role 배정 비율이 13%로 줄어들었음을 확인할 수 있다. [3]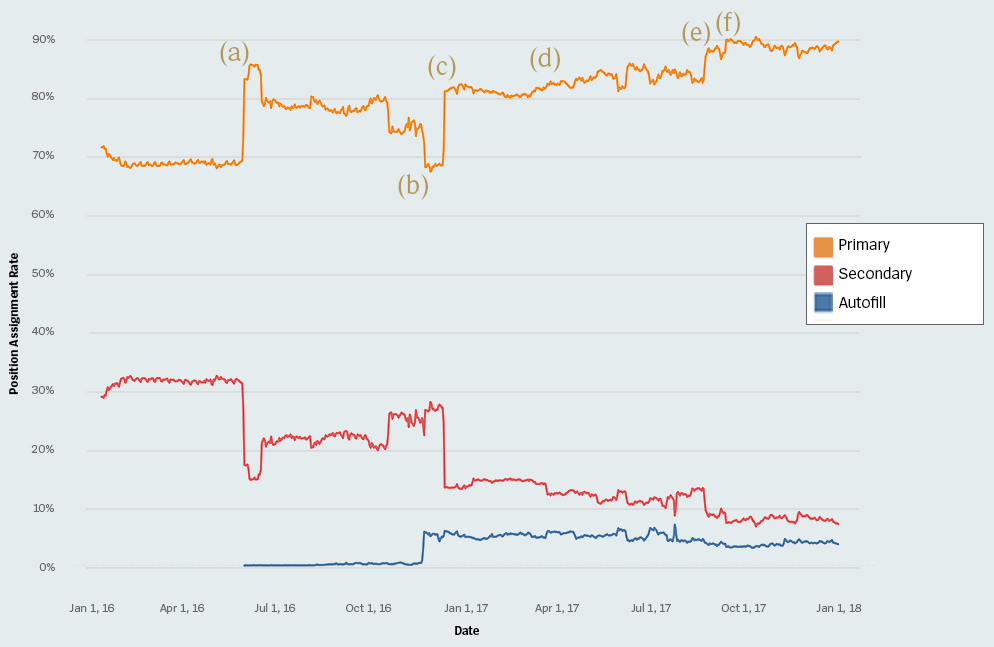 Autofill 시스템이 도입된 (b) 시점 이후 많은 플레이어가 자신이 더욱 선호하는 역할군으로 플레이할 수 있게 되었다.
Autofill 시스템이 도입된 (b) 시점 이후 많은 플레이어가 자신이 더욱 선호하는 역할군으로 플레이할 수 있게 되었다.단순히 생각해보면 각 플레이어는 primary role, secondary role, autofill 중 하나로 배정될 수 있으므로 한 팀에서는 총 가지의 경우의 수가 발생한다. 이는 기존 가지의 약 8배에 달하는 수이다. 이 떄 약간의 발상의 전환을 해보면, 단순히 5가지의 역할군을 5명에게 각각 배정해보는 경우의 수는 가지임을 떠올릴 수 있다. 따라서 해당 방법을 통해 기존의 약 3.75배에 해당하는 연산량으로 줄일 수 있다. 여기에 각 경우에 대한 캐시를 도입하면 시간을 더욱 단축할 수 있을 것이다.
(코드)
AUtofill 점수는 2점으로 하였다.
이렇게 두 가지를 적용한 결과 기존에 비해서 다음과 같은 결과를 얻을 수 있었다.
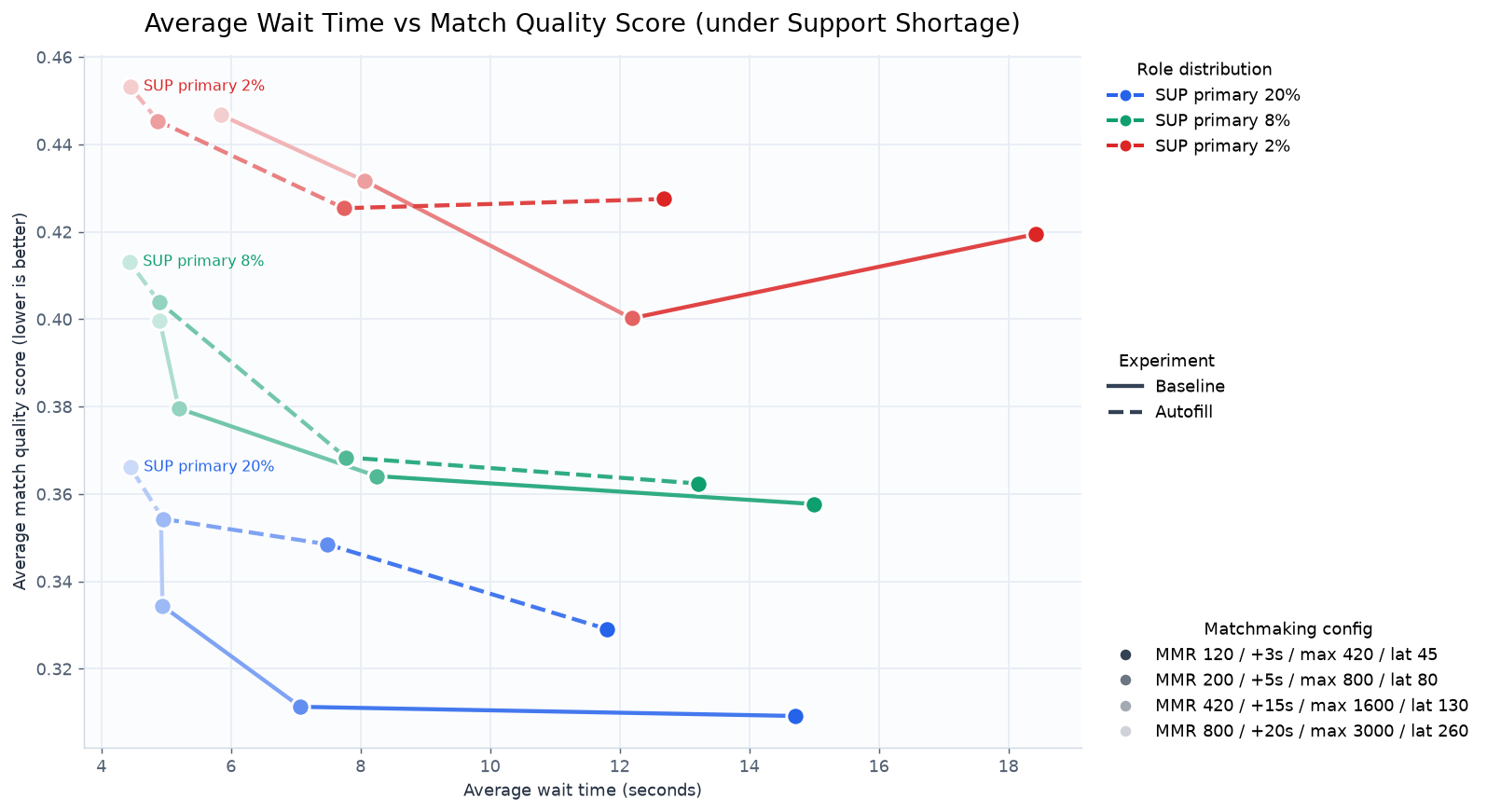 평균 대기 시간에 대한 공정성 점수의 그래프
평균 대기 시간에 대한 공정성 점수의 그래프
우선 대기시간의 경우 는 %증가하고, 는 %감소하였다. 사실 둘다 줄일 수 있는 방법이 있는지 고민해봤는데, ~~~ 떄문에 이론적으로 불가능한 것 같다. 이도 결국 trade-off 관계에 있는 것이다.
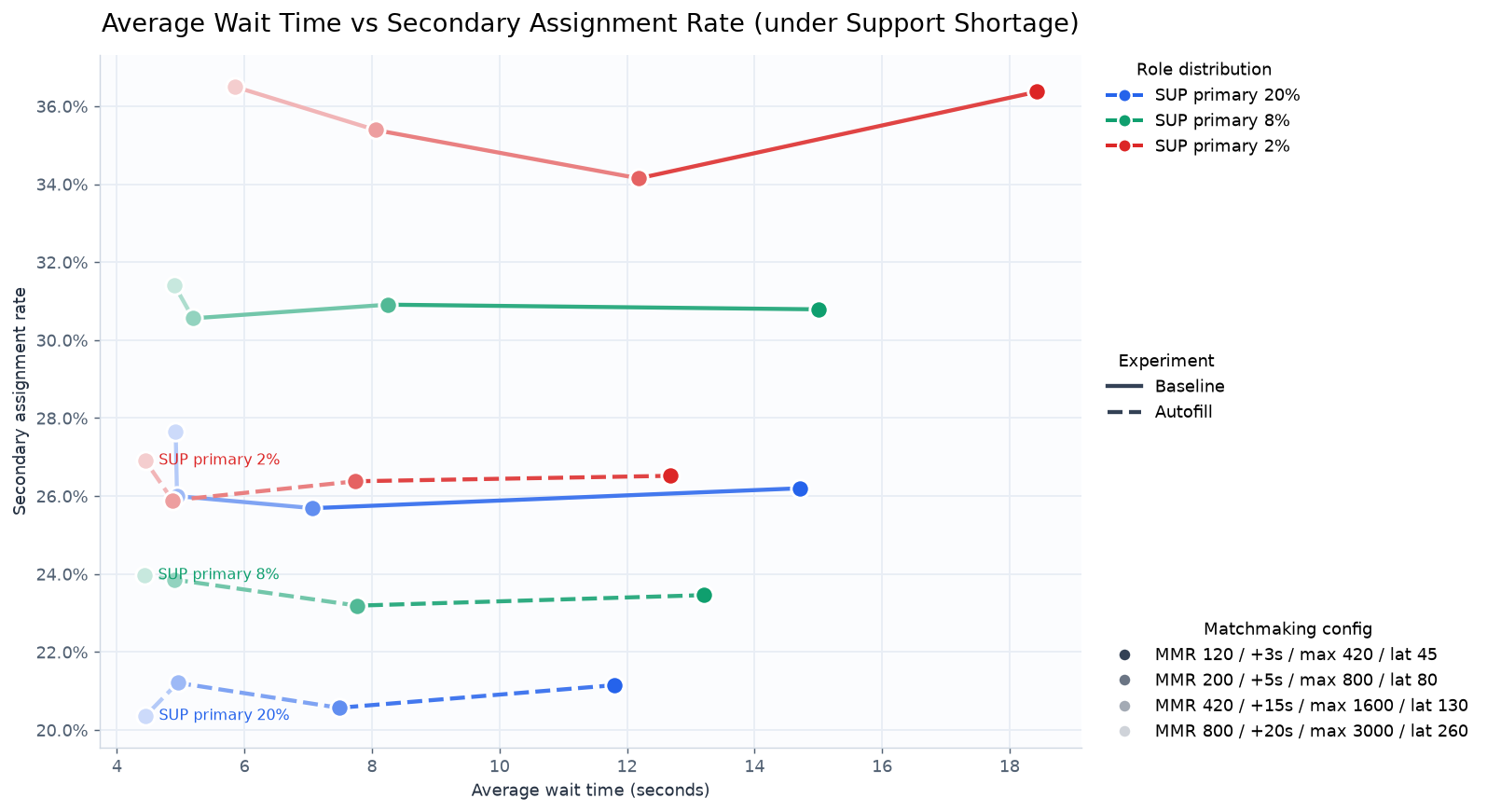 평균 대기 시간에 대한 secondary role 배정 비율의 그래프
평균 대기 시간에 대한 secondary role 배정 비율의 그래프
secondary role 배정 비율은 월등하게 좋아졌다. Riot Games 연구 결과와 비슷한 양상을 띈다
5. 참고문헌
[1] Call of Duty - Matchmaking Series: The Role of Skill in Matchmaking
[2] Riot Games - Matchmaking and Autofill
[3] Riot Games - Making Matchmaking Better
프로젝트 후기
AI 사용법에 대해..
mmr 에 대해서도 단순히 ()이 아니라 Trueskill 등 mmr의 불확실한 정도를 고려해서 점수를 하나의 분포 N(mu,sigma)로 바라보는 개념도 있었다. 이런것도 적용하면 더 도움이 될듯.
어쩌다보니 백엔드 인프라적 프로젝트보다는 그냥 알고리즘 구현 & 데이터 분석 프로젝트와 가까워져버렸다. 다음에 주제 선정할때는 조금 더 심사숙고할 필요가 있을듯 (백엔드 인프라 쪽 공부를 하고 싶다)
© 2025 geniusLHS. All rights reserved.