자유전공학부 AI: RAG 기반 인공지능 챗봇 구축하기
Next.js, FastAPI, Supabase로 구성된 인공지능 챗봇의 아키텍처와 작동 방식
2025-02-02
개요
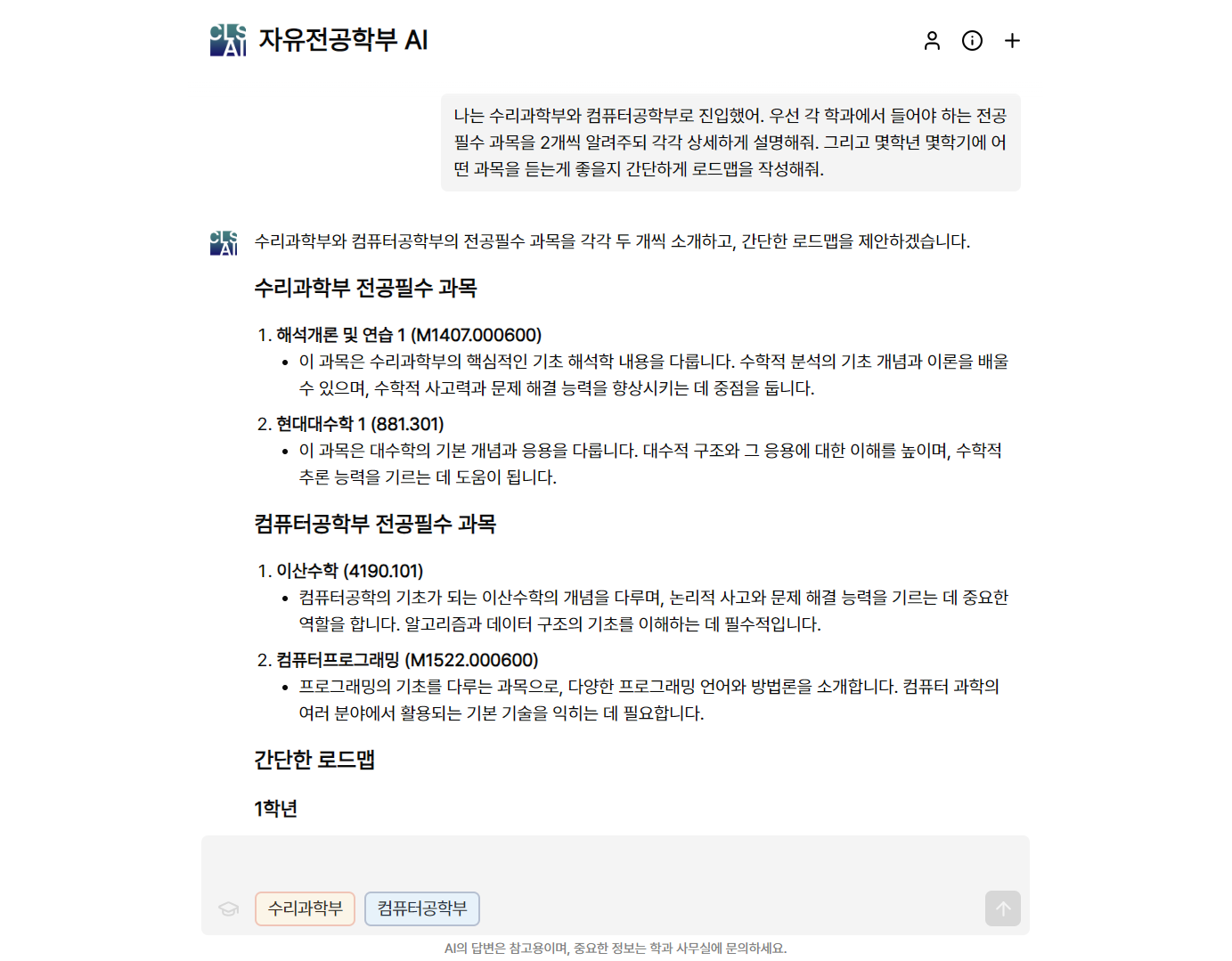
서울대학교의 자유전공학부는 두 개 이상의 전공을 선택하거나 새로운 전공을 설계하여 이수할 수 있는 학부입니다. 대부분의 학생들은 두 개의 전공으로 진입하는데, 이 때 졸업규정을 찾기 위해서는 학과별 홈페이지를 모두 찾아보아야 하고 애매한 부분은 학과 사무실에 문의해야 하는 등 불편함이 있었습니다.
이 문제를 해결하기 위해 자유전공학부 학생회에서는 전공위키 홈페이지를 운영하고 있습니다. 해당 사이트에는 졸업 규정부터 시작해 이미 진입한 선배들의 전공 리뷰, 학과 사무실 문의 답변까지 여러 전공들에 대한 정보가 담겨 있습니다.
저희는 학생들이 필요한 정보를 더 쉽고 빠르게 찾을 수 있도록 하고자 전공위키 내용을 바탕으로 대답을 해주는 인공지능 챗봇을 만들게 되었습니다. 이는 LLM(대규모 언어 모델)이 응답을 생성하기 전에 전공위키에서 관련 내용을 참고하도록 함으로써 구현 가능합니다. 이러한 기술을 RAG(Retrieval-Augmented Generation; 검색 증강 생성)이라고 합니다. 해당 시스템을 어떤 구조로 설계했고, 어떻게 작동 하는지 정리해보았습니다.
자유전공학부 AI 바로가기: https://snuclsai.vercel.app
프로젝트 아키텍처
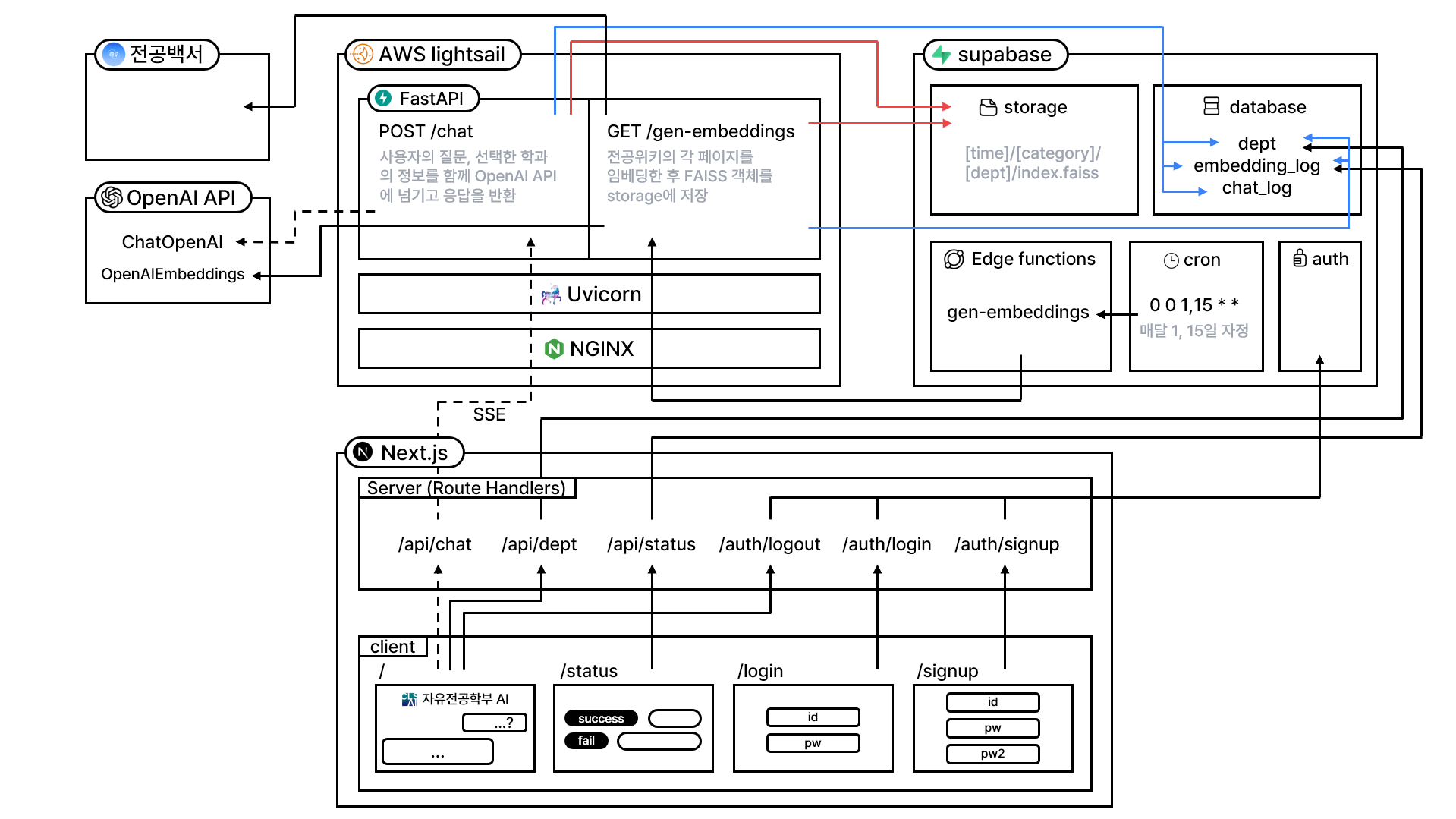
- 프론트엔드 기술 스택: Next.js + Supabase + TailwindCSS + zustand
- 백엔드 기술 스택: FastAPI + Supabase (deploy on AWS lightsail)
기본적으로 임베딩 작업이나 OpenAI API 사용 등 인공지능과 관련된 작업을 많이 하기 때문에 이쪽으로 특화된 언어인 파이썬을 사용하기로 하였습니다. 이에 따라 파이썬 코드를 돌릴 수 있는 서버가 필요해졌고, 비교적 적은 비용이 발생하는 AWS lightsail을 사용하게 되었습니다.
supabase를 데이터베이스로 선택한 이유는 유지보수의 편의성을 위함입니다. 해당 프로젝트는 개발이 끝난 이후에도 유지보수가 필요할 수 있습니다. 개발에 익숙하지 않은 사람도 쉽게 데이터를 열람하고 설정을 변경할 수 있도록 온라인 웹 페이지에서 대시보드를 지원하는 supabase를 선택하였습니다.
기본 작동 방식
백엔드 서버에는 /gen-embeddings와 /chat으로 두 개의 엔드포인트가 있습니다. 이들은 각각 임베딩 작업과 사용자의 질문 처리를 담당합니다.
-
/gen-embeddings: 임베딩 작업 시작백엔드의 /gen-embeddings 에 GET 요청이 오면 임베딩 작업이 시작됩니다. 전공위키의 모든 페이지 정보가 적혀있는 학부·학과·전공 페이지 목록 페이지를 크롤링하여 전체 학과 리스트를 얻고,
dept테이블에 저장합니다. 그리고 각 전공 페이지 별로 임베딩을 하여 얻은index.faiss파일을 supabase storage에 저장합니다. -
/chat: 사용자의 질문 처리사용자가 질문을 하면
/chat엔드포인트에 POST 요청으로 질문의 내용과 선택한 학과 전달됩니다. 백엔드에서는 학과에 해당하는 FAISS 파일들을 supabase storage에서 꺼내오고, 질문과 가장 유사한 내용들 일부 추출합니다. 이를 사용자의 질문과 함께 OpenAI API에 전송하여 응답을 받습니다. 이 결과를 다시 사용자에게 전달해줍니다.
위와 같이 기본적인 임베딩, 검색, 응답 생성만으로도 만족할만한 수준의 대화 퀄리티가 나왔기 때문에 추가로 로직을 구성하지는 않았습니다.
기본적인 원리는 위와 같습니다. 그러나 원활한 서비스 제공을 위해 고려해야할 점들이 더 있습니다.
임베딩 작업 도중 사용자의 질문 처리
임베딩을 하여 얻은 FAISS 파일을 가장 쉽게 저장하는 방법은 supabase storage에서 /[단과대학]/[학과]/index.faiss 경로에 해당 파일을 저장하는 것입니다. 그리고 임베딩 작업이 진행될 때는 각 전공의 임베딩이 끝날때마다 해당 주소의 파일만 업데이트 해주면 됩니다.
위 구현의 첫 번째 문제는 임베딩 작업 도중에 사용자에게 요청이 들어온 경우입니다. 이 경우 임베딩 작업 이전과 이후의 파일들이 뒤섞여있어 일관적이지 않은 정보가 전달될 수 있다는 문제가 생깁니다.
또한 학과들의 리스트를 저장하는 dept 테이블에서도 비슷한 문제가 있습니다. 시간에 따라 전공위키의 학과 리스트에 새로운 학과가 추가되거나 기존의 학과가 삭제될 수 있고, 이 경우 dept 테이블에 변경이 생깁니다. 이 경우에도 변경 중간에 dept 테이블에 요청이 들어오게 된다면 사용자에게는 오염된 내용물이 전달될 것입니다.
두 번째로 모종의 이유로 인해 두 건의 임베딩이 동시에 진행된다면 임베딩 파일이 섞이는 등 문제가 발생할 것입니다.
이러한 문제를 해결하기 위해 임베딩 로그를 기록하는 embedding_log 테이블을 만들고, 임베딩의 진행 상황을 기록하였습니다. 이 테이블을 통한 구체적인 해결 방법은 다음과 같습니다.
- 임베딩이 시작되면 그 순간의 시간
embedding_start_time과 함께status컬럼의 값이 "started"인 데이터를 삽입합니다. - 임베딩 도중에 추가되는 모든 파일에는 어떤 방식으로든
embedding_start_time을 함께 기록합니다.
(저희는 테이블의 경우 컬럼을 만들어 기록하였고, storage의 경우 최상위 폴더의 이름에 기록하였습니다.) - 임베딩이 성공적으로 끝나면 1번의
embedding_start_time과 함께status컬럼의 값이 "success"인 데이터를 삽입합니다. - 임베딩 이전 데이터를 전부 삭제합니다. (즉,
embedding_start_time컬럼의 값이 1번의embedding_start_time의 값과 다른 모든 데이터 삭제)
이렇게 임베딩 로그를 기록하면 위의 두 문제를 동시에 해결할 수 있습니다.
-
/chat경로에 POST 요청이 발생해 임베딩 파일을 찾아야 하는 경우
우선embedding_log테이블에서status컬럼의 값이 "success"인 가장 최신의 로그를 찾습니다.
해당 로그의embedding_start_time값을 가지고 데이터를 찾으면 됩니다. -
/gen-embeddings경로에 GET 요청이 발생해 임베딩 작업을 시작하려는 경우
embedding_log테이블에서 가장 최신의 로그를 찾습니다. 만약 해당 로그의 status 컬럼의 값이 "started"이면 이미 임베딩이 진행중인 것이므로, 이번 임베딩을 취소합니다.
물론 이렇게 구현하면 문제점이 하나 있습니다. 만약 "started" 로그가 찍힌 이후 어떤 이유에서인지 임베딩 중간에 에러가 나 "success" 로그가 찍히지 않았다고 합시다. 그러면 이후에 어떤 임베딩 요청이 들어와도 파이썬은 이미 임베딩이 진행중이라고 판단하고 해당 임베딩을 취소하게 됩니다. 즉, 영원히 임베딩이 멈춥니다.
해당 문제를 해결하기 위해 만약 마지막 "started" 로그가 찍힌 시각이 15분 이전이라면 해당 임베딩이 실패되었다고 판단해 fail 처리하고 새롭게 임베딩을 시작하는 코드를 작성하였습니다.
이렇게 임베딩 로그를 작성하는 방식을 통해 연속적으로 프로그램을 사용할 수 있도록 구현하였습니다.
스트리밍 방식으로 데이터 전달
초기 구현에서는 OpenAI API의 응답을 사용자에게 반환하는 과정이 단순한 HTTP 응답으로 이루어져 있었습니다. 그러나 답변을 전부 생성하는데 대기 시간이 생각보다 길었고, ChatGPT처럼 스트리밍 방식으로 전달해 답변이 전부 완성되지 않아도 일부분씩 데이터를 전송할 수 있도록 구현하게 되었습니다.
이 때 SSE(Server-Sent Events)라는 기술이 사용됩니다. SSE는 클라이언트가 서버로부터 지속적으로 데이터를 받을 수 있도록 하는 기술입니다. 하나의 HTTP 연결을 계속 유지하면서 서버에서 클라이언트로 일방향 스트리밍을 제공할 수 있습니다.
SSE는 웹소켓과도 비교할 수 있습니다. 웹소켓은 양방향 통신을 지원하는 반면, SSE는 서버 → 클라이언트의 단방향 전송만 가능합니다.
실제 구현은 다음과 같습니다. OpenAI API부터 사용자에게 전달되기까지 몇 개의 단계를 걸쳐야 합니다.
ChatOpenAI → FastAPI → Next.js Route Handlers → Next.js Client Components
- ChatOpenAI → FastAPI
async def chat(question: str, context: str, depts: str, user_id: str)
# ...
chat_model = ChatOpenAI(
openai_api_key=OPENAI_API_KEY,
model_name="gpt-4o",
temperature=0.5,
streaming=True,
)
chain = chat_prompt | chat_model
for token in chain.stream({"question": question, "docs": document}):
yield token.content
# ...우선 OpenAI API에서는 스트리밍을 비교적 쉽게 구현할 수 있습니다. streaming=True 옵션을 통해 스트리밍 방식을 사용할 수 있고, 이를 yield 문을 사용해 반환해줍니다.
- FastAPI → Next.js Route Handlers
from fastapi.responses import StreamingResponse
from modules.chat import chat
# ...
async def sse_generator(item: Item):
async for token in chat(item.question, item.context, item.depts, item.user_id):
yield token
@app.post("/chat")
async def post_chat(item: Item):
return StreamingResponse(sse_generator(item), media_type="text/event-stream")FastAPI는 위에서 구현한 chat 함수를 호출하여 그 결과를 StreamingResponse로 감싸 반환합니다.
참고로 FastAPI에서의 응답은 NGINX를 거쳐 Next.js로 전달되는데, 이 때 데이터 조각들이 전달되는 오랜 시간동안 NGINX에서 연결이 끊기지 않도록 따로 설정을 해주어야 합니다.
server {
listen 80;
server_name <IPv4 주소>;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
server_name <IPv4 주소>;
ssl_certificate /etc/nginx/ssl/cert.pem;
ssl_certificate_key /etc/nginx/ssl/key.pem;
location / {
proxy_pass http://localhost:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
}
location /chat {
proxy_pass http://localhost:8000;
proxy_http_version 1.1;
proxy_set_header Connection keep-alive;
proxy_buffering off;
proxy_cache off;
proxy_set_header X-Accel-Buffering no;
keepalive_timeout 650;
}
}- Next.js Route Handlers → Next.js Client Components
import { createClient } from "@/utils/supabase/server";
import { fetch, Agent } from "undici";
export const maxDuration = 60; // 함수 실행 시간 제한 설정 (Next.js 설정)
export async function POST(req: Request) {
const { question, context, depts } = await req.json();
const supabase = await createClient();
const {
data: { user },
} = await supabase.auth.getUser();
const agent = new Agent({
connect: { rejectUnauthorized: false },
});
const res = await fetch(`${process.env.BACKEND_API_URL}/chat`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ question, context, depts, user_id: user?.id }),
dispatcher: process.env.NODE_ENV === "development" ? undefined : agent,
signal: AbortSignal.timeout(60_000),
});
return new Response(res.body as ReadableStream<Uint8Array>, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
Connection: "keep-alive",
"Transfer-Encoding": "chunked",
},
});
}Next.js의 Route Handlers에서 응답을 받고 ReadableStream<Uint8Array>으로 타입 변환 뒤 "text/event-stream" 타입으로 반환해줍니다.
참고로 백엔드 서버에서 도메인을 구입하지 않고 IPv4 주소를 그대로 사용하다 보니 SSL 인증서를 발급받을 수 없었습니다. 자체 서명 인증서로 HTTPS 연결을 구현하긴 했지만 node.js에서는 기본적으로 자체 서명 인증서를 신뢰하지 않았습니다. 프로덕션 빌드에서는 { rejectUnauthorized: false } 설정을 사용하여 해당 문제를 해결하였습니다.
- Next.js Client Components
"use client";
import { useRef, useState, useEffect } from "react";
import { User } from "@supabase/supabase-js";
import { v4 as uuidv4 } from "uuid";
export default function ChatContainer({ user }: { user: User | null }) {
// ...
const handleSubmit = async ({ input, selectedDepts }) => {
const aiMessageId = uuidv4();
addMessage({
id: aiMessageId,
text: "",
isUser: false,
isCompleted: false,
});
const response = await fetch("/api/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
question: input,
context: getContext(messages),
depts: getDepts(selectedDepts),
}),
});
const reader = response.body
.pipeThrough(new TextDecoderStream())
.getReader();
let partialMessage = "";
while (true) {
const { done, value } = await reader.read();
if (done) {
break;
}
partialMessage += value;
updateMessage({
id: aiMessageId,
text: partialMessage,
isUser: false,
isCompleted: false,
});
}
};
return (
// ...
)
}마지막으로 클라이언트 컴포넌트에서 응답을 받아 상태 값으로 전달해주면 사용자가 볼 수 있게 됩니다.
서울대학교 이메일 인증 구현
프로젝트 팀원들과 토의한 결과 해당 웹사이트의 사용 대상은 서울대학교 학생으로 결정되었습니다. 이에 따라 서울대학교 이메일로 회원가입을 해야만 해당 사이트를 사용할 수 있도록 구현하게 되었습니다.
크게 3단계에 걸쳐서 보안이 구현되어 있습니다. 각 과정을 설명드리면 다음과 같습니다.
1. Next.js 클라이언트 (Client Compoents)
const schema = z.object({
email: z.string() \n
.email({ message: "이메일 형식이 올바르지 않습니다." }) \n
.endsWith("@snu.ac.kr", { message: "서울대학교 이메일이어야 합니다." }),
password: z.string().min(6, { message: "비밀번호는 최소 6자 이상이어야 합니다." }),
});클라이언트에서 회원가입 폼을 구현할 때 React Hook Form + Zod를 사용하였습니다.
이 때 Zod에서 .endsWith("@snu.ac.kr") 함수를 사용하여 서울대학교 메일이 아니면 Next.js 서버로 요청을 보내지 않도록 막았습니다.
2. Next.js 서버 (Route Handlers)
import { NextRequest, NextResponse } from "next/server";
import { createClient } from "@/utils/supabase/server";
export async function POST(request: NextRequest) {
const supabase = await createClient();
const { email, password } = await request.json();
if (!email.endsWith("@snu.ac.kr")) {
return NextResponse.json({ error: "Invalid email domain" });
}
const { error } = await supabase.auth.signUp({ email, password });
if (error) {
return NextResponse.json({ error: error.message });
}
return NextResponse.json({ error: null });
}클라이언트에서 받은 데이터를 Next.js 서버에서도 다시 한번 검증해줍니다. 따라서 요청을 중간에서 가로채 변조한 경우에도 서버에서 가로막히게 됩니다.
3. supabase: RLS 설정
ALTER TABLE auth.users ENABLE ROW LEVEL SECURITY;
CREATE POLICY "Allow signup only for @snu.ac.kr emails"
ON auth.users
FOR INSERT
TO authenticated
WITH CHECK (email LIKE '%@snu.ac.kr');마지막으로 supabase에서 RLS 기능을 사용해 데이터베이스 단에서도 보안이 지켜질 수 있도록 하였습니다. '@snu.ac.kr'로 끝나는 이메일만 삽입될 수 있도록 설정하였습니다.
기타 보안: 백엔드와 supabase
supabase 라이브러리를 사용해 손쉽게 사용자 인증을 할 수 있는 프론트엔드(Next.js)와 달리 백엔드(FastAPI)에서는 인증을 구현하려면 유저 아이디를 전송하고 검증하는 등 추가적인 작업이 필요합니다. 무엇보다 사용자의 질문을 최대한 빠르게 처리하기 위해 따로 인증 과정을 구현하고 싶지 않았습니다.
이를 위해서 Next.js 클라이언트와 백엔드 서버를 사이에 직접적인 요청이 가지 않도록 구조를 설계하였습니다. 사용자 입장에서는 백엔드 주소를 알 수 없으므로 백엔드에 인증이 구현되지 않아도 됩니다. 이는 사이에 Next.js 서버 (Route Handlers)를 사용함으로써 구현하였습니다.
또한 supabase 안의 모든 테이블에 대해서도 RLS를 설정하여 관리자 권한이 없다면 아무 데이터도 얻을 수 없도록 하였습니다. 클라이언트에서 supabase로의 모든 요청은 우선 Next.js 서버로 가고, Next.js 서버는 유저 인증을 한 뒤 관리자 권한을 통해 supabase 테이블에서 데이터를 가져와 전달해줍니다.
유지보수
일정 시간마다 자동 임베딩 (supabase cron)
사용자의 질문을 처리하는 /chat 함수에서는 supabase storage에 저장되어 있는 임베딩 값들을 사용합니다. 만약 전공위키의 내용이 업데이트 되었는데도 임베딩을 새로 하지 않는다면 사용자는 계속해서 오래된 정보들을 보게 될 것입니다.
따라서 일정 기간마다 자동으로 임베딩 작업이 시작되도록 하는 기능을 구현하기로 하였습니다. 목표는 일정 기간마다 백엔드 서버의 /gen-embeddings 엔드포인트로 GET 요청을 보내는 것입니다.
supabase cron 기능은 이러한 반복 작업을 굉장히 설정하기 편하게 해줍니다. 또한 pg_net 확장 기능을 통해 웹페이지로의 요청도 보낼 수 있습니다. 그런데 문제는 저희의 백엔드 서버가 자체 서명 인증서를 사용하고 있다는 것입니다. 테스트 결과 pg_net에서는 자체 서명 인증서를 사용하는 서버에는 HTTPS 요청을 보낼 수 없었습니다.
위 방법을 포함해 가능한 방법들을 상세히 살펴보면 다음과 같습니다.
-
supabase cron → 백엔드 엔드포인트:
위에서 설명한 방법입니다. supabase cron에서pg_net확장 기능을 사용해 GET 요청을 보냅니다. 백엔드 서버가 지원하는 프로토콜에 따른 요청 가능 여부는 아래와 같습니다.- HTTP: ⛔
- (self-signed) HTTPS: ⛔
- (Let's Encrypt) HTTPS: ✅
-
supabase cron → supabase edge functions → 백엔드 엔드포인트:
두 번째 방법은 edge functions를 일종의 프록시 서버로 두어 cron은 edge function를 실행시키고, 해당 함수가 백엔드로 GET 요청을 보내는 방식입니다.supabase edge functions는 서버측 타입스크립트 함수로, 사용자에게 가까운 끝단에서 전역적으로 배포됩니다. Deno를 사용해 개발하며, 서버리스 기능을 사용할 수 있습니다.
이 때는 Deno의
fetch함수를 사용합니다. 프로토콜에 따른 요청 가능 여부는 다음과 같습니다.- HTTP: ✅
- (self-signed) HTTPS: ⛔
- (Let's Encrypt) HTTPS: ✅
-
supabase cron → Next.js Route Handlers → 백엔드 엔드포인트:
이번에는 Next.js의 Route Handlers를 거쳐 GET 요청을 보내는 방법입니다. 이 경우 Next.js Route Handlers는 https 연결을 지원하므로pg_net의 요청도 가능하고, Route Handlers에서 백엔드로 요청을 보내는 것은 이미 위에서 구현한 적 있으므로 간단합니다.
그런데 문제는 아무나 해당 주소에 접근할 수 있다는 것입니다. 해당 요청이 사용자가 아닌 서버라는 것을 인증해야 하는데, 해당 과정을 구현하는 것이 더 복잡하다고 느꼈습니다. 또한 supabase와 백엔드 서버가 아닌 제 3자(Next.js)가 로직에 끼어든다는 점에서 구조가 깔끔하지 않습니다.
결론적으로 2번 방법이 가장 적합하다고 생각하여 사용하게 되었습니다.
우선 NGINX 설정 파일에서 HTTP 요청을 받을 수 있도록 수정해줍니다. 저희의 백엔드 서버는 기본적으로 모든 HTTP 요청을 HTTPS로 리다이렉트 하지만, /gen-embeddings 경로로의 요청은 리다이렉트 시키지 않고 그대로 localhost로 전달해주도록 합니다.
server {
listen 80;
server_name <IPv4 주소>;
location /gen-embeddings {
proxy_pass http://localhost:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location / {
return 301 https://$host$request_uri;
}
}
server {
listen 443 ssl;
server_name <IPv4 주소>;
# ...
}다음으로 위에서 뚫어준 경로에 GET 요청을 보내는 gen-embeddings 함수를 만들어 supabase edge functions로 배포해줍니다.
import "jsr:@supabase/functions-js/edge-runtime.d.ts";
Deno.serve(async () => {
const backendUrl = `${Deno.env.get("BACKEND_API_URL_WITH_HTTP")}/gen-embeddings`;
try {
const response = await fetch(backendUrl, { method: "GET" });
const data = await response.text();
console.log("Response:", data);
return new Response(JSON.stringify({ success: true, data }), {
headers: { "Content-Type": "application/json" },
});
} catch (error) {
console.error("Fetch Error:", error);
return new Response(JSON.stringify({ error: (error as Error).message }), {
status: 500,
headers: { "Content-Type": "application/json" },
});
}
});npx supabase functions deploy gen-embeddings그리고 supabase cron 탭에서 해당 edge function을 주기적으로 실행해주는 Job을 생성하면 끝입니다.
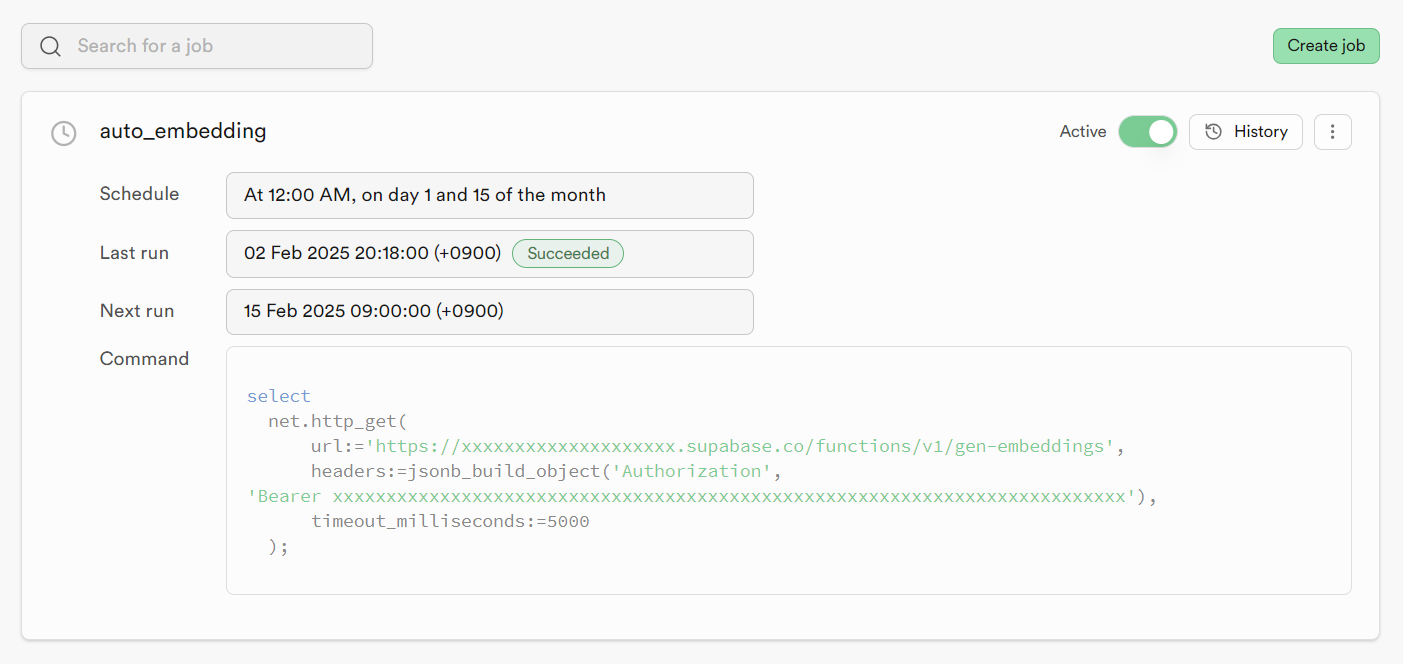 schedule 칸에 "0 0 1,15 * *"을 입력하면 됩니다
schedule 칸에 "0 0 1,15 * *"을 입력하면 됩니다
이렇게 2주마다 자동으로 임베딩이 진행되는 시스템을 구축할 수 있습니다.
저희는 사용자나 관리자가 supabase 대시보드 접속 없이 쉽게 임베딩 작업 현황을 볼 수 있도록 /status 페이지를 추가로 만들었습니다.
 최근 5개의 임베딩 결과를 보여준다
최근 5개의 임베딩 결과를 보여준다
scheduler를 통한 supabase API 자동 호출
저희는 현재 supabase FREE tier를 사용하고 있습니다. 이 경우 일주일동안 Activity가 없으면 프로젝트가 중지(pause)됩니다. 이 경우 다시 접속해서 중지를 풀어줘야 하고, 만약 실수로 까먹어서 90일이 더 지난다면 영원히 중지를 풀지 못하게 됩니다.
Activity가 정확히 무엇을 의미하는지는 분명한 자료가 없지만, 검색 결과 관리자의 대시보드 방문이나 다른 사용자의 API call 등을 의미하는 것 같습니다.
이 귀찮음을 해결하기 위해 FastAPI 서버에서 3일마다 데이터베이스에 간단한 fetch 요청을 날리도록 하였습니다. apscheduler 라이브러리를 사용하면 쉽게 구현 가능합니다.
from modules.scheduler import fetch_to_keep_supabase_active
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
scheduler.add_job(fetch_to_keep_supabase_active, "interval", days=3)
scheduler.start()import os
from apscheduler.schedulers.background import BackgroundScheduler
from supabase import create_client
from config.logging_config import logger
from dotenv import load_dotenv
load_dotenv()
SUPABASE_URL = os.getenv("SUPABASE_URL")
SUPABASE_KEY = os.getenv("SUPABASE_KEY")
def fetch_to_keep_supabase_active():
supabase_client = create_client(SUPABASE_URL, SUPABASE_KEY)
try:
res = supabase_client.table("dept").select("*").limit(1).single().execute()
if res.data != None:
logger.info(f"successfully fetched dept to keep supabase active")
except Exception as e:
logger.error(f"Error fetching dept to keep supabase active: {e}")
마치며
지금까지 자유전공학부 AI의 구조와 작동 방식에 대해 살펴보았습니다.
해당 프로젝트에 참여한 팀원은 총 세 명이며, 2025년 1월 한 달간 진행되었습니다.
인공지능 챗봇을 실제로 구현해보며 전체적인 서비스의 구조 설계에 대해 더욱 깊게 이해할 수 있었습니다. 또한 SSE 통신이나 supabase의 cron, edge functions 등 다양한 기술들을 실제 프로덕트에 사용해볼 수 있어 좋았습니다.
이 글이 RAG 시스템을 구축하려는 분들께 도움이 되길 바랍니다.
© 2025 geniusLHS. All rights reserved.